Beyond Text: Meta AI Framework Lets LLMs 'See' and 'Hear' Without Specific Training

Large Language Models (LLMs) have fundamentally reshaped our interaction with information, demonstrating remarkable fluency and reasoning within the realm of text. Yet, the world isn't just text; it's a rich tapestry of images, sounds, and videos. Integrating these diverse modalities into AI systems typically involves complex architectures and extensive, task-specific training data. Now, researchers from Meta AI, collaborating with UT Austin and UC Berkeley, have unveiled a surprisingly straightforward, training-free framework that imbues standard LLMs with a wide range of multimodal capabilities.
Their approach, detailed in a paper titled "LLMs can see and hear without any training", introduces the Multimodal Iterative LLM Solver, or MILS. Instead of building a monolithic multimodal model from scratch or fine-tuning an LLM on multimodal datasets, MILS cleverly orchestrates existing, pre-trained models in a novel feedback loop that operates purely at inference time – meaning no additional training is required to adapt it to a new task.
The Generator-Scorer Loop
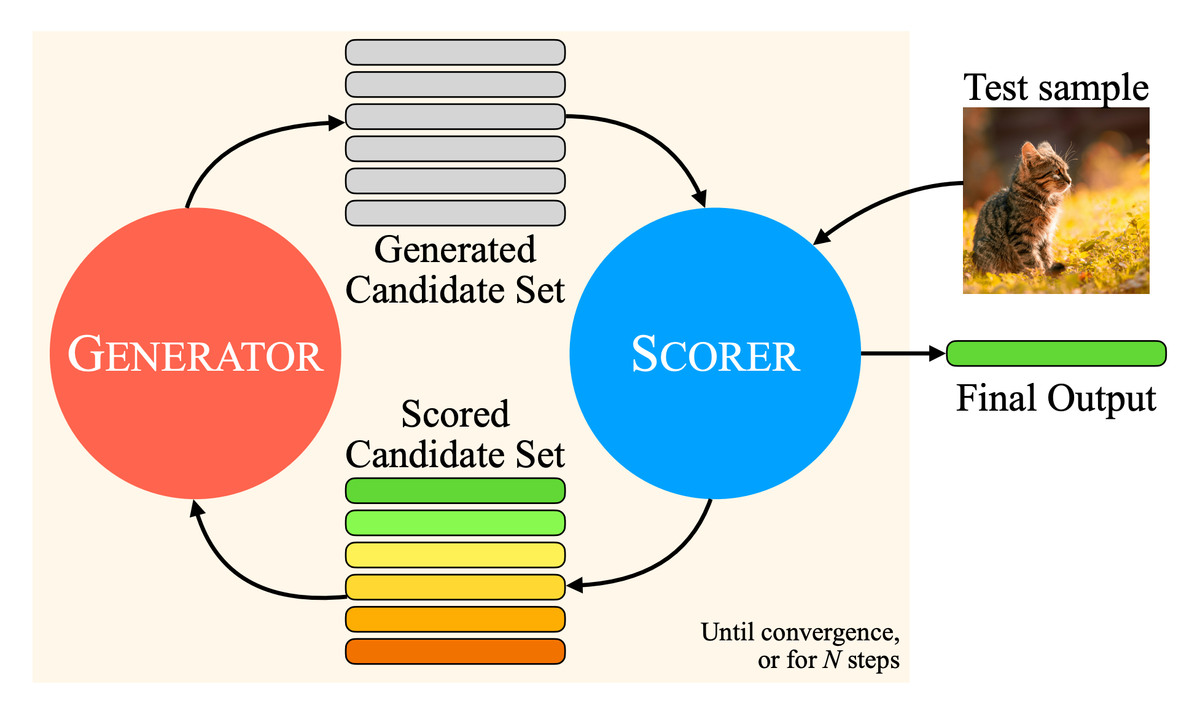
At its heart, MILS employs two key components: a GENERATOR and a SCORER.
- The GENERATOR is typically a standard, off-the-shelf LLM (like Llama 3.1 8B, used in their experiments). Its job is to propose candidate solutions for a given multimodal task. For instance, if the task is image captioning, the GENERATOR produces a batch of potential captions. If the task is improving image generation, it might propose rewrites of an initial text prompt.
- The SCORER is a pre-trained model capable of evaluating the quality of the GENERATOR's proposals against the input media. For image captioning, this could be a model like SigLIP or CLIP, which assesses the similarity between a generated caption and the actual image content. For evaluating generated image quality, a model like PickScore, trained to predict human preferences, might be used.
The process is iterative: The GENERATOR produces candidates. The SCORER evaluates them, assigning a score to each. These scores, along with the corresponding candidates, are fed back into the GENERATOR's prompt. Armed with this feedback ("these captions scored higher, these scored lower"), the LLM generates a new, hopefully improved, set of candidates in the next step. This cycle repeats – optimizing the output purely through iterative refinement at test time – until the results converge or a set number of steps is reached.
Crucially, this process is gradient-free. MILS doesn't require backpropagating error signals through the models, which simplifies the framework and makes it highly flexible – different GENERATORs and SCORERs can potentially be swapped in and out depending on the task.
From Captioning to Cross-Modal Arithmetic
The researchers demonstrate MILS's versatility across a striking range of applications:
Zero-Shot Captioning: MILS was applied to generate captions for images (using MSCOCO dataset), videos (MSR-VTT), and audio (Clotho). Without any training on captioning data, MILS achieved state-of-the-art or competitive results compared to previous zero-shot methods, particularly excelling on metrics like METEOR and SPICE that capture semantic meaning better than simple word overlap. For instance, using Llama 3.1 8B as the GENERATOR and SigLIP as the SCORER for images, MILS outperformed prior specialized zero-shot captioning techniques like MeaCap, despite MILS's simpler architecture.
Improving Text-to-Image Generation: MILS can act as an automatic prompt enhancer. By using an LLM to iteratively rewrite an initial text prompt and a SCORER (like PickScore) to evaluate the resulting images generated by a text-to-image model (like Latent Diffusion Model or FLUX.1), MILS consistently produced images that human evaluators preferred for both visual quality and faithfulness to the original prompt concept. The LLM effectively learns to refine prompts for better aesthetics and clarity.
Style Transfer: MILS was adapted for image editing. Given a content image and a style image, the LLM GENERATOR proposed "edit prompts," while the SCORER (using Gram matrix distance to measure style similarity) guided the process. MILS successfully generated images blending the original content with the desired style, again without specific training for this task.
Cross-Modal Arithmetic: Perhaps the most intriguing demonstration is combining concepts across modalities. MILS's ability to invert multimodal embeddings (like those from ImageBind) back into text is key here. The researchers showed they could take an image (e.g., boats) and an audio clip (e.g., birds chirping), use MILS to generate textual descriptions for each, use an LLM to combine these descriptions ("boats on the water with birds chirping nearby"), and then feed this combined text into a text-to-image model to generate a novel image reflecting both concepts.
Significance: Emergent Capabilities Without Training
The core significance of MILS lies in its "emergent zero-shot generalization." Most zero-shot AI aims to generalize to new data within a task it was trained for (or explicitly adapted to). MILS demonstrates generalization to entirely new tasks (like audio captioning or prompt improvement) using a configuration, not specific training. It suggests that sophisticated multimodal understanding and generation can arise from the structured interaction of powerful, but individually limited, pre-trained models.
This contrasts sharply with approaches requiring large paired datasets (e.g., image-caption pairs) and end-to-end training or fine-tuning for each multimodal task. MILS offers a more modular and potentially data-efficient path forward, leveraging the strong reasoning and text-generation capabilities already present in LLMs.
Limitations and Future Directions
The authors acknowledge that MILS isn't magic. Its performance is inherently limited by the capabilities of the chosen GENERATOR and SCORER. A better LLM can propose more diverse and relevant candidates, while a more accurate SCORER provides better guidance. The iterative process can also be computationally more intensive at inference time compared to a single forward pass through a trained model. Furthermore, tasks like style transfer are limited by the nuance captured by the SCORER (e.g., Gram matrix might miss fine-grained texture details).
Despite these limitations, MILS presents a compelling proof-of-concept. As foundational LLMs and multimodal scoring models continue to improve, frameworks like MILS stand to benefit directly, potentially becoming more powerful and efficient. The researchers suggest future work could involve applying MILS to other modalities and tasks, such as spatial or 3D data.
In essence, MILS offers a fascinating glimpse into how the reasoning power of LLMs can be channeled to coordinate other AI models, effectively allowing them to perceive and interact with multimodal information in surprisingly sophisticated ways, all without the need for direct multimodal training. It's a paradigm that emphasizes clever orchestration over task-specific learning, potentially opening up new avenues for building flexible and adaptable AI systems.
Read the original research paper here: LLMs can see and hear without any training