The Art of AI Anonymity: "Anti-Adversarial" Learning Shields Your LLM Inputs


As we increasingly turn to Large Language Models (LLMs) like ChatGPT for everything from drafting emails to complex problem-solving, a thorny issue emerges: the privacy of the information we feed into them. When your prompts, containing potentially sensitive details, are sent to cloud-based LLMs, how can you be sure your private data stays private? Researchers from Shanghai Jiao Tong University have proposed an elegant solution called PromptObfus, detailed in their recent paper, "Anti-adversarial Learning: Desensitizing Prompts for Large Language Models." Their approach cleverly obscures sensitive information in your prompts without derailing the LLM's ability to understand and respond to your core request.
The core challenge is that traditional privacy-preserving techniques like homomorphic encryption or federated learning can be too clunky, computationally intensive, or simply impractical for interacting with the black-box APIs many LLMs offer. PromptObfus takes a different, more nimble path, introducing a concept the authors term "anti-adversarial learning."
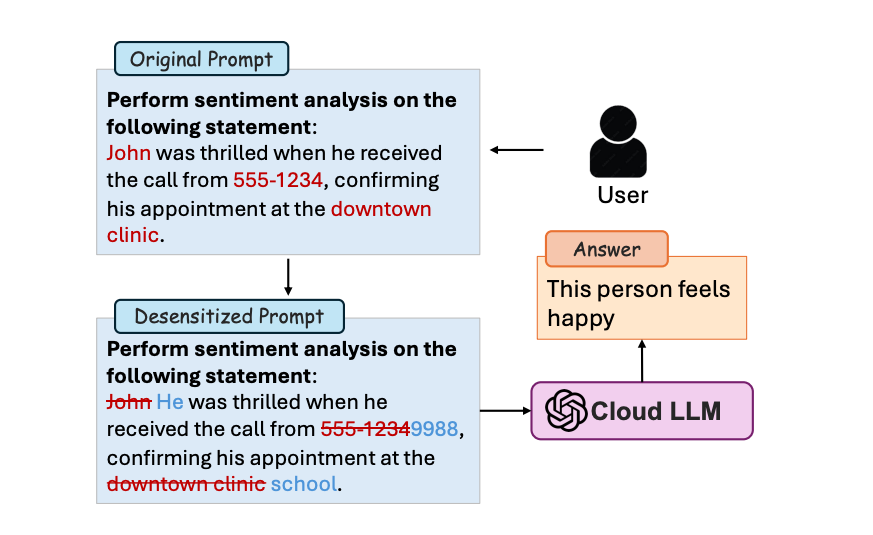
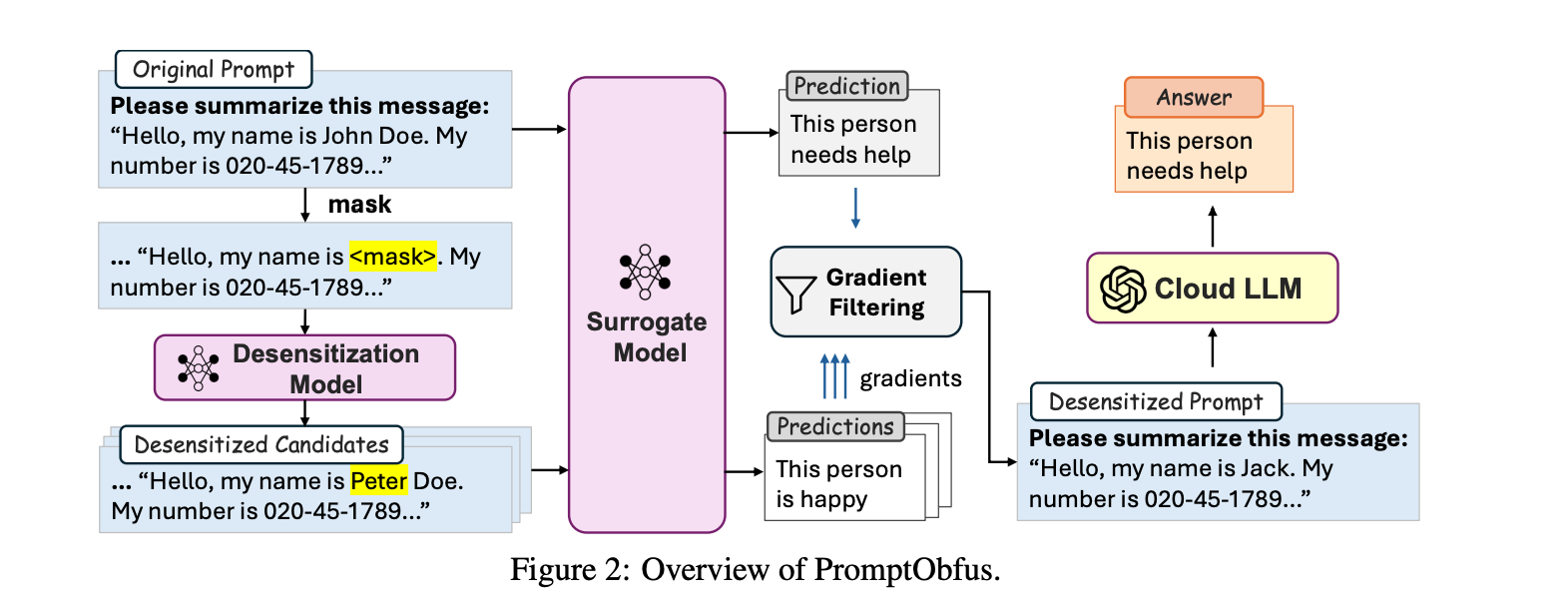
PromptObfus first identifies potentially private words in your prompt using techniques like Named Entity Recognition (NER) to spot names, locations, and other explicit identifiers. It also randomly masks other words to tackle implicitly sensitive data. Then, a locally run "desensitization model" (think of it as a creative wordsmith) suggests alternative words for these masked spots. Crucially, these suggestions are filtered to ensure they are semantically different from the original sensitive word, preventing easy re-identification.
But how does it pick the best replacement—one that hides the private data but doesn't confuse the main LLM? This is where a second local "surrogate model" comes in. This smaller model acts as a stand-in for the large, remote LLM. It assesses how much each candidate replacement word would likely alter the final output of the task (e.g., sentiment analysis or question answering). By looking at the "gradient feedback"—a measure of how sensitive the output is to changes in input—PromptObfus selects the replacement word that causes the least disruption. It’s like finding a disguise that makes you unrecognizable but still allows you to deliver your message clearly.
The researchers tested PromptObfus on several natural language processing tasks, including sentiment analysis, topic classification, and question answering. The results are promising. For instance, on a sentiment analysis task, PromptObfus managed to reduce the success rate of PII (Personally Identifiable Information) inference attacks to zero, while the task accuracy only dropped by a mere 2.75% compared to using the original, unobfuscated prompt. This demonstrates a strong balance between privacy protection and utility, outperforming several existing baseline methods.
While effective, PromptObfus isn't a silver bullet. The authors acknowledge limitations, such as the challenge of comprehensively identifying all implicit privacy words—those whose sensitivity depends heavily on context. Furthermore, for complex tasks like question answering, general-purpose surrogate models might not be as precise as task-specific ones, which require more data to train.
Nevertheless, PromptObfus offers a significant step forward. It provides a practical method for users to protect their sensitive information when interacting with powerful cloud-based LLMs, without needing access to the LLM's internal workings. By cleverly changing the "face" of private data while keeping its "purpose" intact, this research helps us navigate the evolving landscape of AI with a bit more confidence in our digital privacy. You can delve into the technical specifics in the original research paper.